


Research HighlightsApplied Genomics to Improve Soybean Seed Protein
By Trupti Joshi, University of Missouri Columbia
USB and other organizations have funded sequencing of hundreds of soybean genomes, generating a large quantity of data. The research funded in his project aims to use the data to understand genetics controlling traits important to soybean production. This ambitious $62,397 project is assembling an “allele catalogue” of natural variants for every gene in the soybean genome (think of the human gene for hair color, where an individual might have the brown allele, the blonde allele, the black allele, etc.). This catalogue can be used to identify new genes controlling traits incorporated into elite germplasm develop new lines with improved genetic qualities.
The researchers began with the a test case of the recently discovered gene thought to be responsible for the high oil content found in many commercial soybean varieties. The allele of this gene found in most U.S. grower’s soybean is likely having a negative impact on the protein. It is possible that by changing this allele, the amount of protein can be increased. To identify new alleles of this gene, soybeans known to have higher protein, such as wild soybean and Japanese and Korean cultivars were investigated. The research identified least six distinct alleles of this gene among cultivated and wild soybean, of which Alleles #1 and #5 are the predominant versions. Allele #1 is the major allele responsible for high oil (and low protein) present in all of the sequenced Chinese cultivars and 98.6% of the North American cultivars (see figure). In the U.S. and China, Allele #5 is largely nonexistent. However, in Japanese and Korean cultivars, where protein concentration is substantially higher, the frequency of Allele #5 is 25% higher than it is in the Chinese and North American cultivars. Even more telling, in wild soybean, where protein concentration is highest, Allele #5 is the most prevalent at 55%.
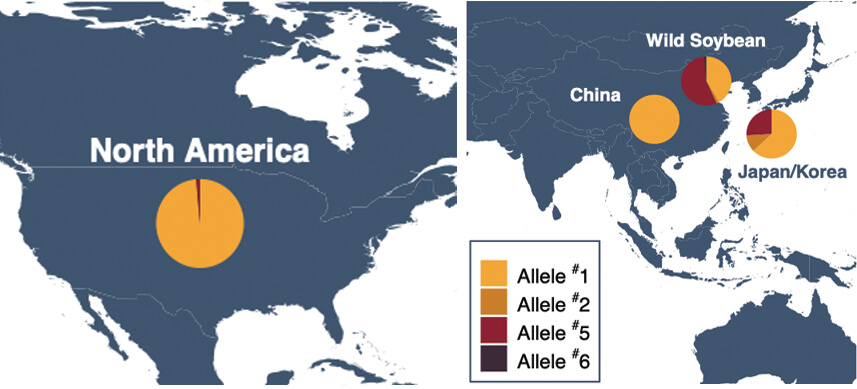
The observed trend between protein content and frequency of Allele #5 suggests that this allele may be contributing to the higher protein concentrations observed in wild soybean, as well as Japanese and Korean cultivars. Thus, protein in U.S. soybean may be increased by incorporating this allele into the genome of new cultivars. Alleles #2, #3, #4 and #6 are all rare. Some are present only in wild soybean, and some are present only in groups of soybeans not depicted in the figure. Their roles are currently under investigation.
Further testing in the field will be needed to confirm that the incorporation of Allele #5 improves seed protein content under typical growing conditions. However, this example illustrates one way in which the allele catalogue can be exploited to identify genetic resources that can improve traits in that are important to soybean growers.
This project is one of the research projects funded by USB in 2019 as a part of the iPOP process (innovative proposal). The overarching project is called Genomic Tools to Enable Trait Discovery. The information and bioinformatics tools developed in this project will be made available to public and private researchers, accelerating trait discovery and integration of those traits into new soybean lines that farmers can grow.
Published: May 8, 2020




